

Hi folks, welcome to a simplified exploration of Apache Kafka, the powerhouse of real-time data streaming! Whether you're a beginner or looking to refresh your knowledge, this article aims to demystify Kafka's complex structure and explain how it efficiently manages data streams. Let's dive in with a clear roadmap and practical insights.
What is Kafka?
At its core, Apache Kafka is an open-source event streaming platform, widely utilized for constructing real-time data pipelines and streaming applications. It excels in handling high-throughput, fault-tolerant, and scalable data streaming. Think of Kafka as the backbone that ensures a seamless flow of data across various systems.
Apache Kafka is an open-source real-time stream processing platform.
Events in Kafka
In the definition above, streams refer to a continuous and unbounded flow of data records or events. Imagine Twitter, where each tweet, like, or follow is an event. In Kafka, an event might look like this: {user_id: 123, event_type: "post", content: "Hello, world!"}. It's the basic data unit that Kafka processes, much like a tweet in our analogy. This event is serialized by the producer by the serializer of your choice into binary form and then deserialized by the consumer upon consumption. The key here is used for partitioning. Kafka uses append-only log files to store these events which also makes it cheap.
Confused already by all the jargon, worry not I'll explain it all. Just keep going.
Producers and Consumers
Producers create events (like writing a letter), and Consumers process them (like receiving a letter). Kafka's magic lies in its ability to ensure the producer's letters reach the right consumer mailboxes, even if some mailboxes are temporarily out of service. Note that Kafka provides the decoupling between these producers and consumers, i.e., a producer produces these events to a Broker, and a consumer polls the Broker and consumes the events. Suppose you post a letter to a friend. You simply put it in a mailbox instead of going to your friend yourself and giving the letter. The whole process of the letter being delivered is abstracted from you. Such decoupling ensures fault tolerance as even if one producer or consumer goes down, they do not affect the others. Consumers are part of a Consumer Group that Kafka identifies by a unique name. Only one consumer of a consumer group will receive the event. This allows scaling out consumers with the guarantee of only-once message delivery.
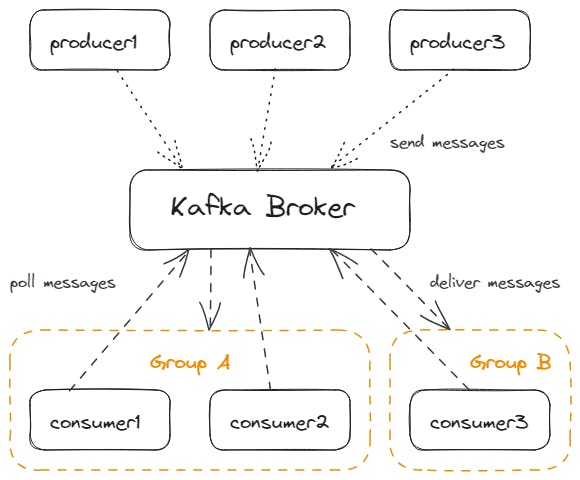
Topics and Partitions
Topics are like specific mailboxes or channels for different types of letters (events). Each mailbox (topic) has different slots (partitions) to organize letters (events). Kafka ensures letters are read in the order they’re received, maintaining the story's flow. You publish an event on a particular topic and the consumer then polls the message by subscribing to the topic. Hence, A topic is a logical channel or category to which producers publish messages. Each topic contains a partition(s). In turn, the events live in these partitions.
Are you wondering how Kafka ensures that the messages get consumed in the same order that they are produced? This is implemented using offsets. The events living in the partitions are assigned an ordered number i.e. an offset within that partition. The partition also stores the offsets of the events that are already consumed by the consumer. This ensures that events are delivered to the consumer in the same order as they were stored in the partition. The consumer provides acknowledgment when it has successfully consumed an event and then only the partition moves to the next offset. This guarantees the successful delivery of the event.
When a consumer subscribes to a topic one partition is assigned to it and the consumer listens to the events of this partition only.

Ideally, we should have as many consumers as partitions, so that every consumer can be assigned to exactly one of the partitions. If we have more consumers than partitions, those consumers won’t receive messages from any partition and if we have fewer consumers than partitions, consumers will receive messages from multiple partitions, which conflicts with optimal load balancing.
Here, you should also understand that producers do not necessarily send messages to only one partition. Every event is assigned to a partition randomly unless specified otherwise.
Assigning Specific Partitions to a Producer
The ways of writing an event to a particular partition are as follows:
Producers and Partition Choice:
Producers can send messages to specific partitions, like choosing which slot to drop a letter into, hence bypassing the default partition assignment mechanisms.
Key-Based Partitioning:
Think of this as sorting letters based on the recipient's name, ensuring related letters stay together. If a message has a key, Kafka uses a hash function to calculate a hash value based on that key. This hash value determines the partition to which the message will be sent. Messages with the same key will always have the same hash value and consequently end up in the same partition. This is useful for scenarios where you want related messages to be stored together in the same partition, ensuring order and grouping.
Partition Count and Key Hashes:
Ideally, the number of distinct key hashes (resulting from different keys) should be equal to or greater than the number of partitions in the Kafka topic. This helps distribute messages evenly across partitions. If you have more partitions than unique key hashes, some partitions may receive multiple messages with the same key hash.
Sticky Partitioner as a Fallback:
If a producer does not explicitly specify a partition and a message does not have a key, Kafka employs a mechanism called the Sticky Partitioner to determine the partition for the message. The Sticky Partitioner is designed to ensure that messages with the same key are consistently sent to the same partition, even though no explicit partition is chosen. It does this by maintaining a mapping between keys and partitions and using this mapping to send messages to the appropriate partitions. Each producer has its partitioner so to ensure consistent partitioning you should work with a single producer.
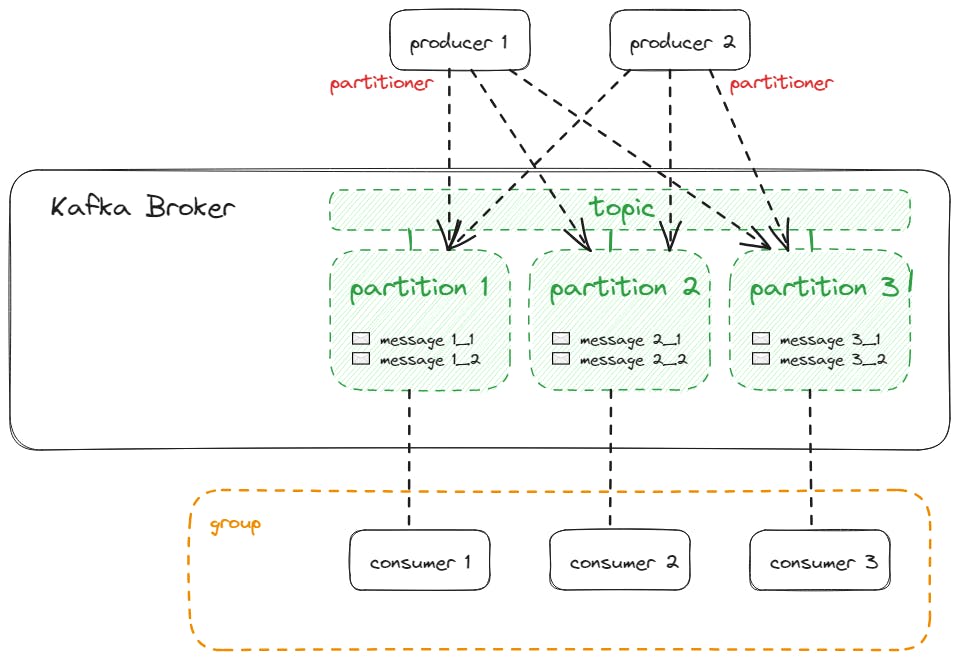
Clusters and Partition Replicas
Kafka implements master-slave architecture when it comes to handling multiple brokers. This means that it creates a cluster of multiple brokers with the same partitions one partition being the leader. This also ensures fault tolerance in case one broker fails you don't lose its data. You can provide a replication factor to create n brokers. For example, if you provide a replication factor of 3 your cluster is resilient to up to two replica failures. Remember to create as many brokers as the replication factor as Kafka does not create the topic until the number of brokers becomes equal to the replication factor.
In this architecture, Kafka declares one of the partitions as the partition leader. The producer delivers the events to this partition only and then the leader synchronizes with all the other brokers. Consumers also poll from the leader maintaining the synchronization of offset increment. Also, Kafka creates different partition leaders in different brokers distributing partition-leading to multiple brokers.
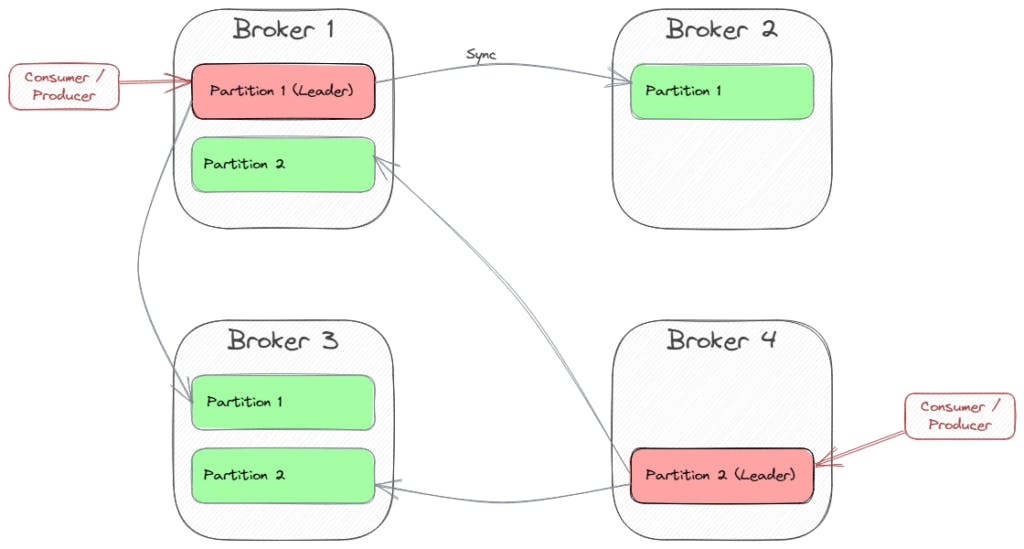
Here, Broker 1 is the leader of Partition 1, and Broker 4 is the leader of Partition 2. So each client will connect to those brokers when sending or polling messages from these partitions.
Concluding It All
If you put producers and consumers together with a cluster of three brokers that manage a single topic with three partitions and a replication factor of 3, you'll get something like this -

Imagine a bustling town square (Kafka) where numerous people (producers) are sending messages across, and numerous others (consumers) are receiving them, all organized by a sophisticated system of mailboxes and slots (topics and partitions). That's Kafka in a nutshell.
Happy Learning !!